Catalog
The catalog in Mission Control is implemented under the hood using config-db - A JSON based configuration management database (CMDB) that scrapes data from external systems.

The catalog is comprised of:
- Config Items are individual reaources e.g.
Pod,EBS,IAM Role,postgres.conffile - Changes recorded against config items either through automatic change detection (diffs) or from sources like
AWS CloudTrailorKubernetes Events - Insights recorded against config items from external sources like
AWS Trusted AdvisororTrivy - Relationships between configuration items
Scraping
Config items, insights and change are ingested using scrapers which are jobs that run periodically, scrapers come in 2 types:
Native scrapers ingest config items from common sources like AWS, Kubernetes, Azure and automatically add metadata and relationshops
Custom scrapers ingest raw data from Files and SQL queries the results of which need to mapped to metadata and relationships manually.
Relationships
Config items can be related to other items using both hard and soft links.
Hard Links represent a physical relationship, e.g. A pod is always a child of namespace, hard links are created automatically by the relevant scraper or can be created by specifying Parent Type and ID in custom scrapers.
Soft Links represent logical relationships and can have directionality. e.g. Node is related to a pod that runs on it, and a pod is related to an Persistent Volume that is attached the pod. Soft Links are created automatically by some scrapers e.g. Using ownerRef in kubernetes and subnet-id in AWS. Custom soft links can be created using a Relationship transformation.
Config Items
JSON
Config items are stored as jsonb fields in Postrgres, The JSON used is typically returned by resource provider e.g. kubectl get -o json or aws --output=json - The UI will convert from JSON to YAML when showing the config.
XML / Properties / etc.
Custom scrapers can ingest non-JSON config which is represented as:
{
"format": "xml",
"content": "<root>..</root>"
}
The UI will format and render XML appropriately.
Features
- Scrape data from typical data sources like AWS, GCP, Azure, Kubernetes and Github
By doing this, Config DB enables you to view and search the change history of your configuration across multiple dimensions (node, zone, environment, application, technology, etc...) as well as compare and view the differences between configurations across environments.
It is able to scan multiple configuration sources including
- AWS Cloud Resources
- Azure Devops - Azure Devops Pipeline runs
- Files - On a local filesystem, git or HTTP
- Files - Kubernetes - Files inside a running Kubernetes pod
- Kubernetes - Kubernetes resources
- SQL - Data available via queries on MySQL, SQL Server, and Postgres databases
- Trivy - Security scanning of Kubernetes clusters
Each configuration has:
- Configuration - Normally JSON, but XML and properties files are also available
- Insights - Security, cost, performance, and other recommendations from scanners including AWS Trusted Advisor, AWS Config rules, etc...
- Changes - Either change directly on the config (recorded as diff change type) or changes identified via AWS Cloudtrail, etc...
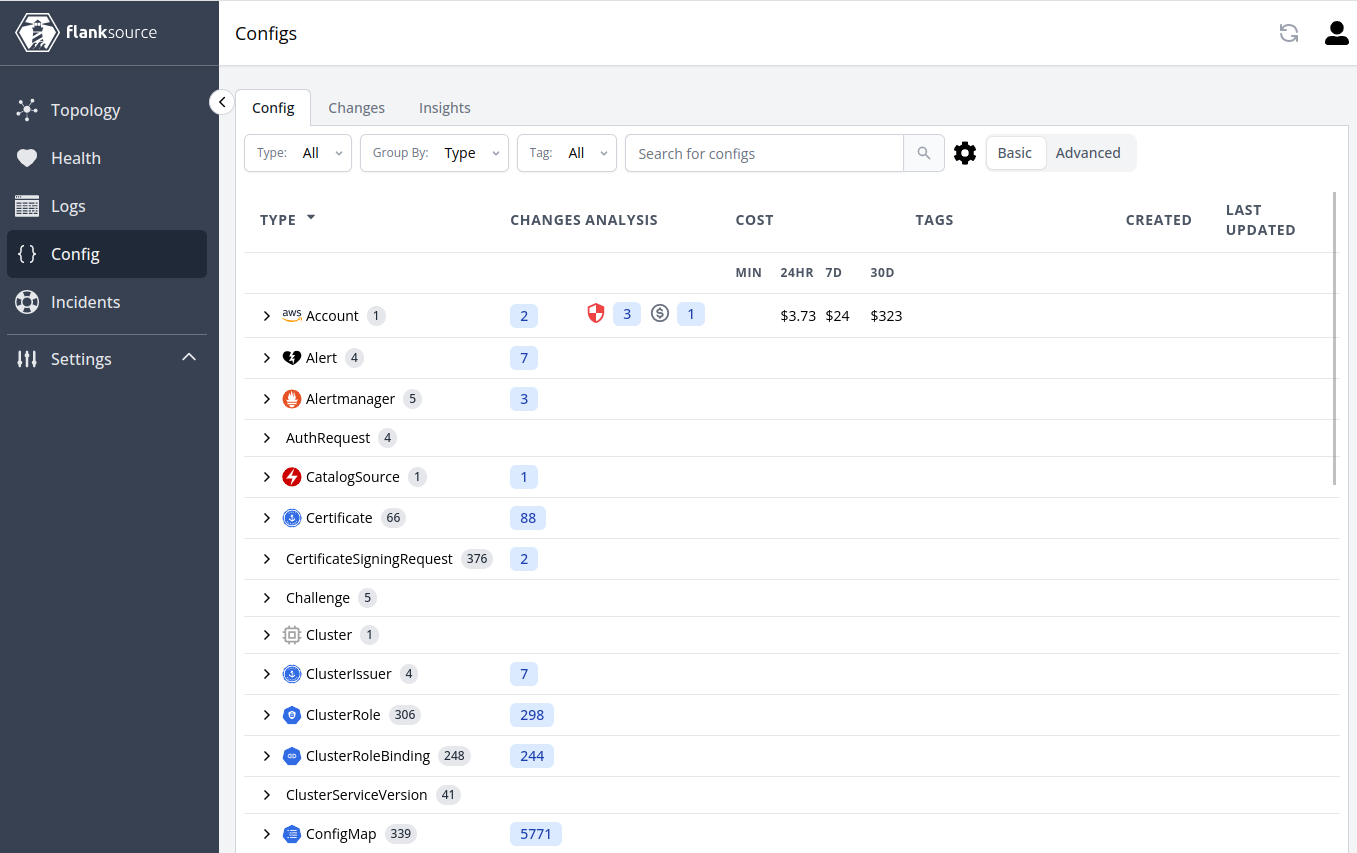
A configuration summary is shown below:
 import { name } from "file-loader"
import { name } from "file-loader"